NebulaAIFlow中的数据加载器组件
信息
加载器组件现位于组件菜单的**功能包(Bundles)**分类下。
加载器组件用于从各类数据源(如数据库、网站和本地文件)获取数据并导入NebulaAIFlow。
在流程中使用加载器组件
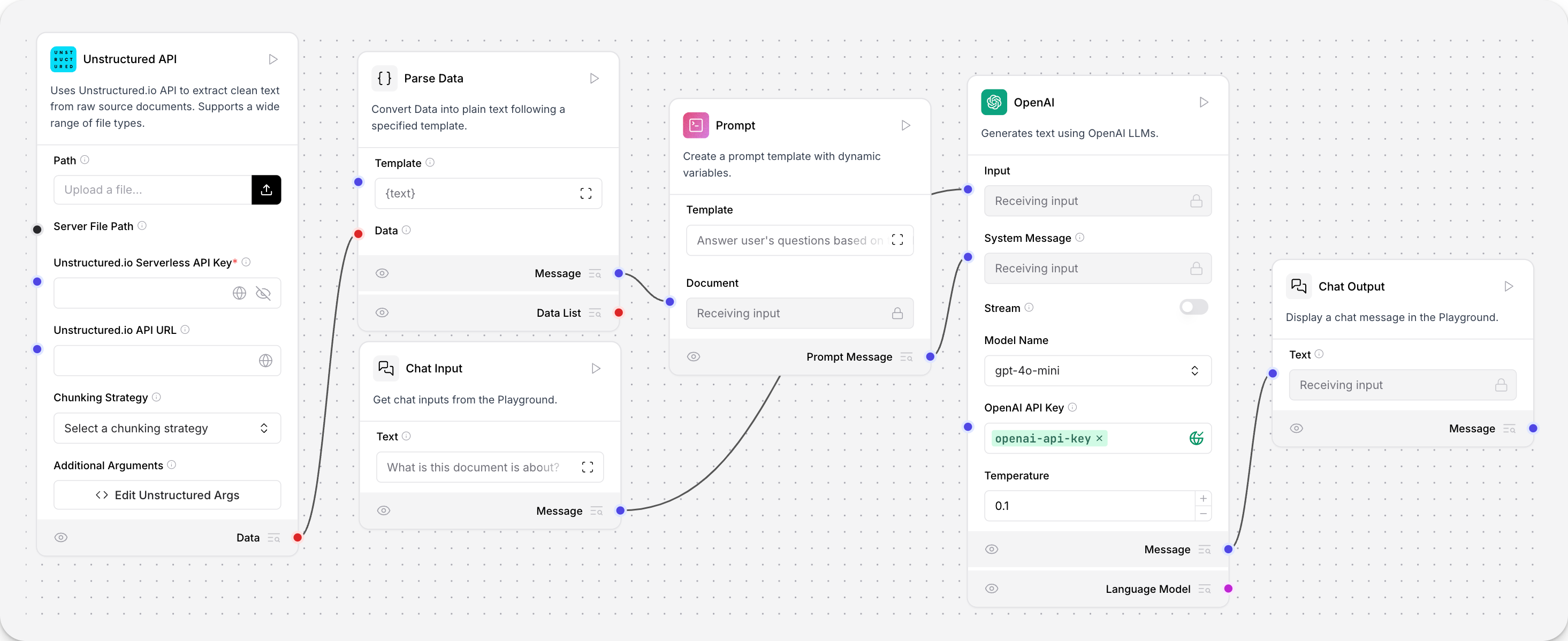
本示例流程创建了一个基于文档的问答聊天机器人。
通过Unstructured.io加载器组件从本地机器加载文件,并将其解析为结构化的数据对象(Data)列表。
这些加载的数据将指导Open AI组件对用户问题的回答。
Confluence加载器
该组件集成Confluence协作平台,用于加载和处理文档。通过LangChain的ConfluenceLoader从指定Confluence空间获取内容。
输入参数
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| url | 站点URL | Confluence空间的基础URL(如https://company.atlassian.net/wiki) |
| username | 用户名 | Atlassian用户邮箱(如email@example.com) |
| api_key | API密钥 | Atlassian API密钥(创建地址:Atlassian) |
| space_key | 空间密钥 | 要访问的Confluence空间密钥 |
| cloud | 使用云服务 | 是否使用Confluence Cloud(默认:true) |
| content_format | 内容格式 | 指定内容格式(默认:STORAGE) |
| max_pages | 最大页数 | 最大获取页数(默认:1000) |
输出结果
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| data | 数据 | 包含已加载Confluence文档的数据对象列表 |
Git加载器
该组件使用LangChain的GitLoader从指定Git仓库获取和加载文档。
输入参数
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| repo_path | 仓库路径 | Git仓库的本地路径 |
| clone_url | 克隆URL | Git仓库克隆地址(可选) |
| branch | 分支 | 加载文件的分支(默认:'main') |
| file_filter | 文件过滤器 | 文件筛选模式(如'.py'仅包含py文件,'!.py'排除py文件) |
| content_filter | 内容过滤器 | 基于文件内容的正则过滤模式 |
输出结果
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| data | 数据 | 包含已加载Git仓库文档的数据对象列表 |
Unstructured加载器
该组件使用Unstructured.io无服务API将文件加载并解析为结构化的数据对象(Data)列表。
输入参数
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| file | 文件 | 待解析文件路径(支持类型见文档) |
| api_key | API密钥 | Unstructured.io无服务API密钥 |
| api_url | API地址 | Unstructured API的可选URL地址 |
| chunking_strategy | 分块策略 | 文档分块策略(可选:"", "basic", "by_title", "by_page", "by_similarity") |
| unstructured_args | 附加参数 | 传给Unstructured.io API的可选参数字典 |
输出结果
| 参数名 | 显示名称 | 说明 |
|---|---|---|
| data | 数据 | 包含已解析文件内容的数据对象列表 |