NebulaAIFlow模型组件
模型组件使用大型语言模型生成文本。
有关参数的更多信息,请参阅具体组件的文档。
在流程中使用模型组件
模型组件接收输入和提示来生成文本,生成的文本会发送到输出组件。
模型输出也可以发送到语言模型端口,然后传递给解析数据组件,在那里输出可以被解析成结构化的数据对象。
这个示例在聊天机器人流程中使用了OpenAI模型。更多信息,请参阅基础提示流程。
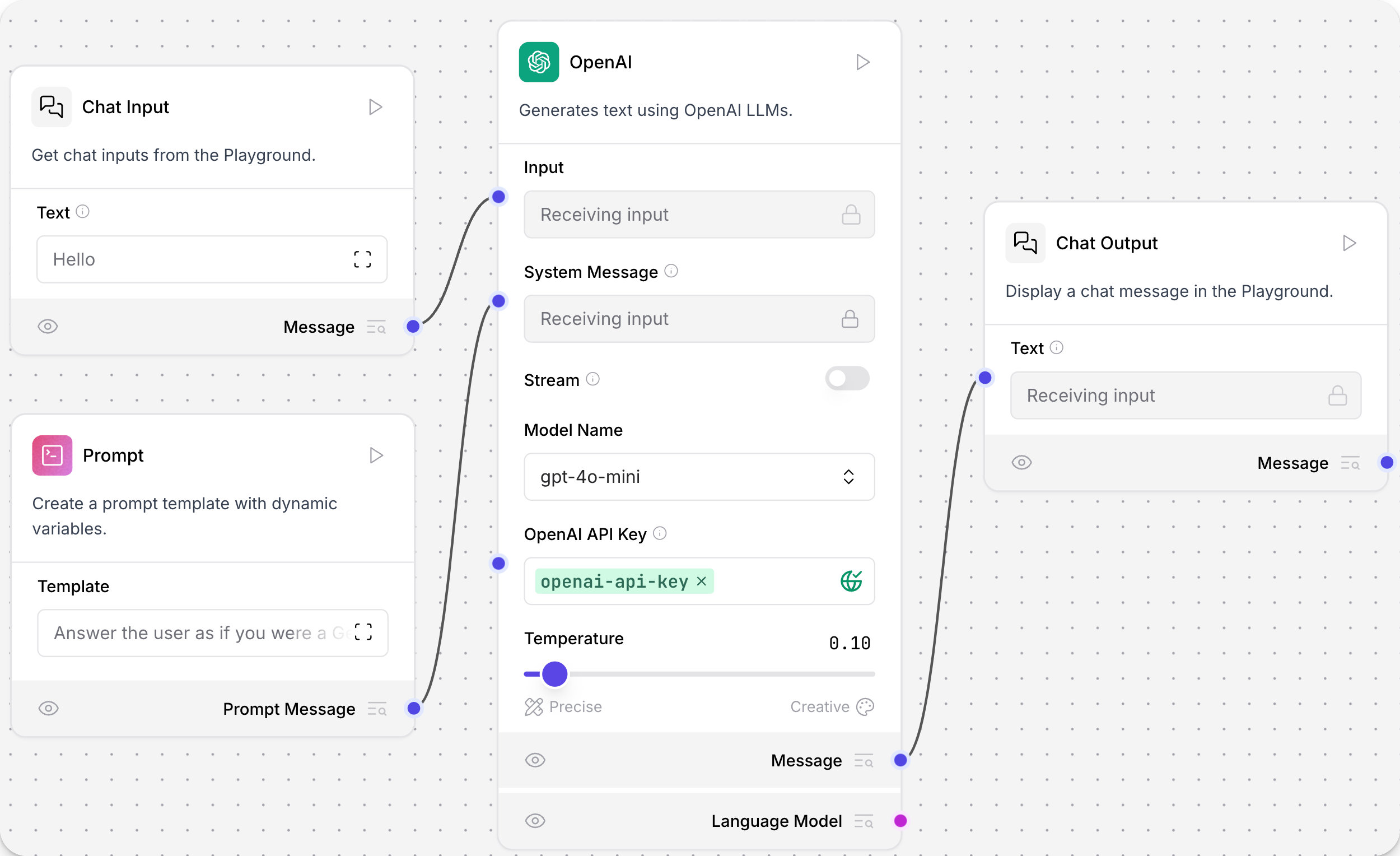
AI/ML API
此组件使用AIML API创建ChatOpenAI模型实例。
更多信息,请参阅AIML文档。
输入参数
| 名称 | 类型 | 说明 |
|---|---|---|
| max_tokens | 整数 | 要生成的最大令牌数。设置为0表示无限制令牌。范围:0-128000。 |
| model_kwargs | 字典 | 模型的其他关键字参数。 |
| model_name | 字符串 | 要使用的AIML模型名称。选项在AIML_CHAT_MODELS中预定义。 |
| aiml_api_base | 字符串 | AIML API的基础URL。默认为https://api.aimlapi.com。 |
| api_key | 密钥字符串 | 用于模型的AIML API密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| seed | 整数 | 控制任务的可重复性。 |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatOpenAI实例。 |
Amazon Bedrock
此组件使用Amazon Bedrock LLMs生成文本。
更多信息,请参阅Amazon Bedrock文档。
输入参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model_id | 字符串 | 要使用的Amazon Bedrock模型ID。选项包括各种模型。 |
| aws_access_key | 密钥字符串 | 用于身份验证的AWS访问密钥。 |
| aws_secret_key | 密钥字符串 | 用于身份验证的AWS密钥。 |
| credentials_profile_name | 字符串 | 要使用的AWS凭证配置文件名称(高级)。 |
| region_name | 字符串 | AWS区域名称。默认值:us-east-1。 |
| model_kwargs | 字典 | 模型的其他关键字参数(高级)。 |
| endpoint_url | 字符串 | Bedrock服务的自定义端点URL(高级)。 |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatBedrock实例。 |
Anthropic
此组件允许使用Anthropic聊天和语言模型生成文本。
更多信息,请参阅Anthropic文档。
输入参数
| 名称 | 类型 | 说明 |
|---|---|---|
| max_tokens | 整数 | 要生成的最大令牌数。设置为0表示无限制令牌。默认值:4096。 |
| model | 字符串 | 要使用的Anthropic模型名称。选项包括各种Claude 3模型。 |
| anthropic_api_key | 密钥字符串 | 用于身份验证的Anthropic API密钥。 |
| temperature | 浮点数 | 控制输出的随机性。默认值:0.1。 |
| anthropic_api_url | 字符串 | Anthropic API的端点。如果未指定,默认为https://api.anthropic.com(高级)。 |
| prefill | 字符串 | 预填充文本以引导模型的响应(高级)。 |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatAnthropic实例。 |
Azure OpenAI
This component generates text using Azure OpenAI LLM.
For more information, see the Azure OpenAI documentation.
输入参数
| 名称 | 类型 | 说明 |
|---|---|---|
| Model Name | Model Name | Specifies the name of the Azure OpenAI model to be used for text generation. |
| Azure Endpoint | Azure Endpoint | Your Azure endpoint, including the resource. |
| Deployment Name | Deployment Name | Specifies the name of the deployment. |
| API Version | API Version | Specifies the version of the Azure OpenAI API to be used. |
| API Key | API Key | Your Azure OpenAI API key. |
| Temperature | Temperature | Specifies the sampling temperature. Defaults to 0.7. |
| Max Tokens | Max Tokens | Specifies the maximum number of tokens to generate. Defaults to 1000. |
| Input Value | Input Value | Specifies the input text for text generation. |
| Stream | Stream | Specifies whether to stream the response from the model. Defaults to False. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of AzureOpenAI configured with the specified parameters. |
Cohere
This component generates text using Cohere's language models.
For more information, see the Cohere documentation.
Inputs
| Name | Display Name | Info |
|---|---|---|
| Cohere API Key | Cohere API Key | Your Cohere API key. |
| Max Tokens | Max Tokens | Specifies the maximum number of tokens to generate. Defaults to 256. |
| Temperature | Temperature | Specifies the sampling temperature. Defaults to 0.75. |
| Input Value | Input Value | Specifies the input text for text generation. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of the Cohere model configured with the specified parameters. |
DeepSeek
This component generates text using DeepSeek's language models.
For more information, see the DeepSeek documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | Maximum number of tokens to generate. Set to 0 for unlimited. Range: 0-128000. |
| model_kwargs | Dictionary | Additional keyword arguments for the model. |
| json_mode | Boolean | If True, outputs JSON regardless of passing a schema. |
| model_name | String | The DeepSeek model to use. Default: deepseek-chat. |
| api_base | String | Base URL for API requests. Default: https://api.deepseek.com. |
| api_key | SecretString | Your DeepSeek API key for authentication. |
| temperature | Float | Controls randomness in responses. Range: [0.0, 2.0]. Default: 1.0. |
| seed | Integer | Number initialized for random number generation. Use the same seed integer for more reproducible results, and use a different seed number for more random results. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatOpenAI实例。 |
Google Generative AI
This component generates text using Google's Generative AI models.
For more information, see the Google Generative AI documentation.
Inputs
| Name | Display Name | Info |
|---|---|---|
| Google API Key | Google API Key | Your Google API key to use for the Google Generative AI. |
| Model | Model | The name of the model to use, such as "gemini-pro". |
| Max Output Tokens | Max Output Tokens | The maximum number of tokens to generate. |
| Temperature | Temperature | Run inference with this temperature. |
| Top K | Top K | Consider the set of top K most probable tokens. |
| Top P | Top P | The maximum cumulative probability of tokens to consider when sampling. |
| N | N | Number of chat completions to generate for each prompt. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of ChatGoogleGenerativeAI configured with the specified parameters. |
Groq
This component generates text using Groq's language models.
For more information, see the Groq documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| groq_api_key | SecretString | API key for the Groq API. |
| groq_api_base | String | Base URL path for API requests. Default: https://api.groq.com (advanced). |
| max_tokens | Integer | The maximum number of tokens to generate (advanced). |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.1. |
| n | Integer | Number of chat completions to generate for each prompt (advanced). |
| model_name | String | The name of the Groq model to use. Options are dynamically fetched from the Groq API. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of ChatGroq configured with the specified parameters. |
Hugging Face API
This component sends requests to the Hugging Face API to generate text using the model specified in the Model ID field.
The Hugging Face API is a hosted inference API for models hosted on Hugging Face, and requires a Hugging Face API token to authenticate.
In this example based on the Basic prompting flow, the Hugging Face API model component replaces the Open AI model. By selecting different hosted models, you can see how different models return different results.
-
Create a Basic prompting flow.
-
Replace the OpenAI model component with a Hugging Face API model component.
-
In the Hugging Face API component, add your Hugging Face API token to the API Token field.
-
Open the Playground and ask a question to the model, and see how it responds.
-
Try different models, and see how they perform differently.
For more information, see the Hugging Face documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| model_id | String | The model ID from Hugging Face Hub. For example, "gpt2", "facebook/bart-large". |
| huggingfacehub_api_token | SecretString | Your Hugging Face API token for authentication. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
| max_new_tokens | Integer | Maximum number of tokens to generate. Default: 512. |
| top_p | Float | Nucleus sampling parameter. Range: [0.0, 1.0]. Default: 0.95. |
| top_k | Integer | Top-k sampling parameter. Default: 50. |
| model_kwargs | Dictionary | Additional keyword arguments to pass to the model. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of HuggingFaceHub configured with the specified parameters. |
IBM watsonx.ai
This component generates text using IBM watsonx.ai foundation models.
To use IBM watsonx.ai model components, replace a model component with the IBM watsonx.ai component in a flow.
An example flow looks like the following:
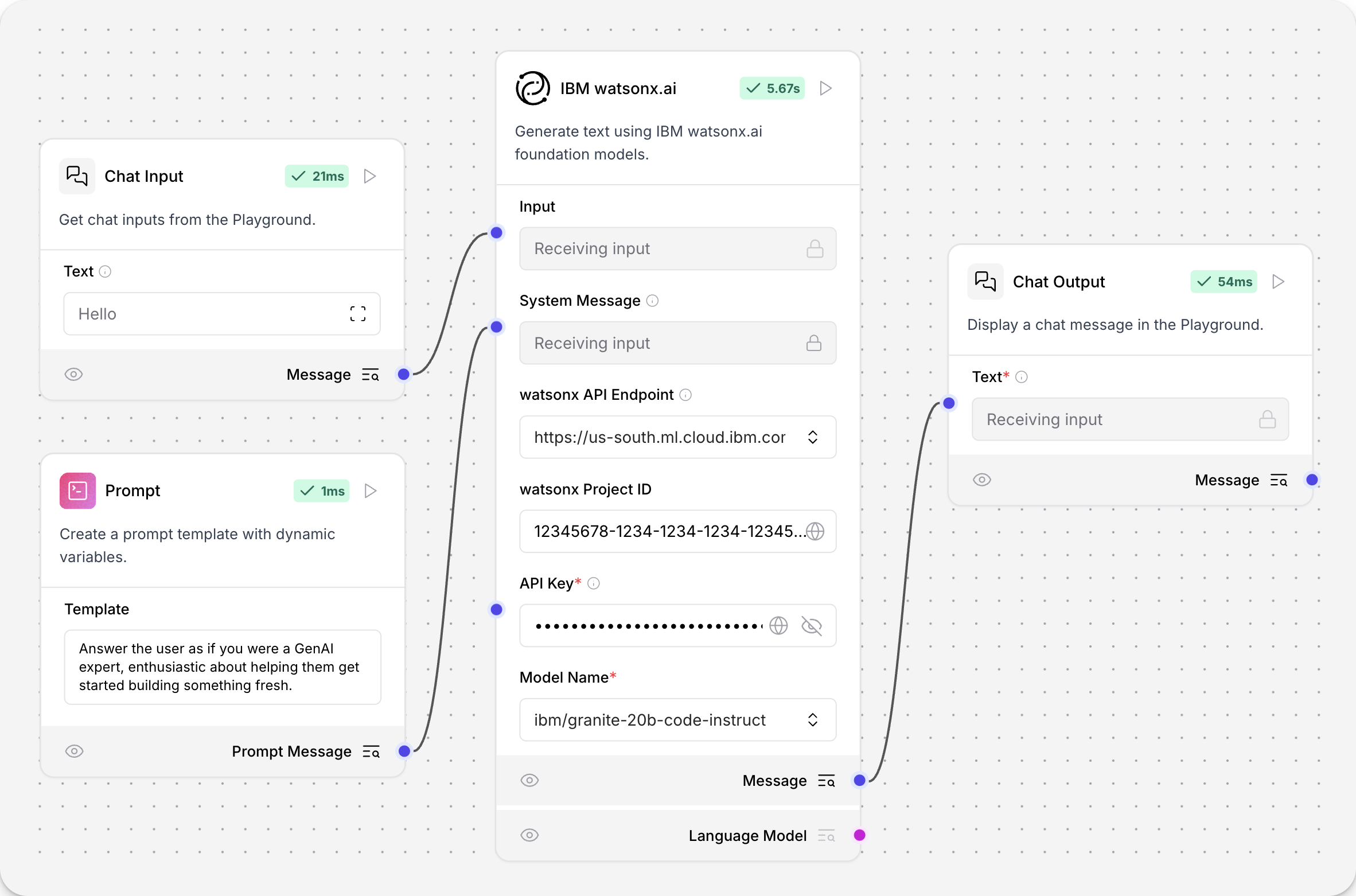
The values for API endpoint, Project ID, API key, and Model Name are found in your IBM watsonx.ai deployment. For more information, see the Langchain documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| url | String | The base URL of the watsonx API. |
| project_id | String | Your watsonx Project ID. |
| api_key | SecretString | Your IBM watsonx API Key. |
| model_name | String | The name of the watsonx model to use. Options are dynamically fetched from the API. |
| max_tokens | Integer | The maximum number of tokens to generate. Default: 1000. |
| stop_sequence | String | The sequence where generation should stop. |
| temperature | Float | Controls randomness in the output. Default: 0.1. |
| top_p | Float | Controls nucleus sampling, which limits the model to tokens whose probability is below the top_p value. Range: Default: 0.9. |
| frequency_penalty | Float | Controls frequency penalty. A positive value decreases the probability of repeating tokens, and a negative value increases the probability. Range: Default: 0.5. |
| presence_penalty | Float | Controls presence penalty. A positive value increases the likelihood of new topics being introduced. Default: 0.3. |
| seed | Integer | A random seed for the model. Default: 8. |
| logprobs | Boolean | Whether to return log probabilities of output tokens or not. Default: True. |
| top_logprobs | Integer | The number of most likely tokens to return at each position. Default: 3. |
| logit_bias | String | A JSON string of token IDs to bias or suppress. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of ChatWatsonx configured with the specified parameters. |
Language model
This component generates text using either OpenAI or Anthropic language models.
Use this component as a drop-in replacement for LLM models to switch between different model providers and models.
Instead of swapping out model components when you want to try a different provider, like switching between OpenAI and Anthropic components, change the provider dropdown in this single component. This makes it easier to experiment with and compare different models while keeping the rest of your flow intact.
For more information, see the OpenAI documentation and Anthropic documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| provider | String | The model provider to use. Options: "OpenAI", "Anthropic". Default: "OpenAI". |
| model_name | String | The name of the model to use. Options depend on the selected provider. |
| api_key | SecretString | The API Key for authentication with the selected provider. |
| input_value | String | The input text to send to the model. |
| system_message | String | A system message that helps set the behavior of the assistant (advanced). |
| stream | Boolean | Whether to stream the response. Default: False (advanced). |
| temperature | Float | Controls randomness in responses. Range: [0.0, 1.0]. Default: 0.1 (advanced). |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of ChatOpenAI or ChatAnthropic configured with the specified parameters. |
LMStudio
This component generates text using LM Studio's local language models.
For more information, see LM Studio documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| base_url | String | The URL where LM Studio is running. Default: "http://localhost:1234". |
| max_tokens | Integer | Maximum number of tokens to generate in the response. Default: 512. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 2.0]. Default: 0.7. |
| top_p | Float | Controls diversity via nucleus sampling. Range: [0.0, 1.0]. Default: 1.0. |
| stop | List[String] | List of strings that will stop generation when encountered (advanced). |
| stream | Boolean | Whether to stream the response. Default: False. |
| presence_penalty | Float | Penalizes repeated tokens. Range: [-2.0, 2.0]. Default: 0.0. |
| frequency_penalty | Float | Penalizes frequent tokens. Range: [-2.0, 2.0]. Default: 0.0. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of LMStudio configured with the specified parameters. |
Maritalk
This component generates text using Maritalk LLMs.
For more information, see Maritalk documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens. Default: 512. |
| model_name | String | The name of the Maritalk model to use. Options: sabia-2-small, sabia-2-medium. Default: sabia-2-small. |
| api_key | SecretString | The Maritalk API Key to use for authentication. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.5. |
| endpoint_url | String | The Maritalk API endpoint. Default: https://api.maritalk.com. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of ChatMaritalk configured with the specified parameters. |
Mistral
This component generates text using MistralAI LLMs.
For more information, see Mistral AI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens (advanced). |
| model_name | String | The name of the Mistral AI model to use. Options include open-mixtral-8x7b, open-mixtral-8x22b, mistral-small-latest, mistral-medium-latest, mistral-large-latest, and codestral-latest. Default: codestral-latest. |
| mistral_api_base | String | The base URL of the Mistral API. Defaults to https://api.mistral.ai/v1 (advanced). |
| api_key | SecretString | The Mistral API Key to use for authentication. |
| temperature | Float | Controls randomness in the output. Default: 0.5. |
| max_retries | Integer | Maximum number of retries for API calls. Default: 5 (advanced). |
| timeout | Integer | Timeout for API calls in seconds. Default: 60 (advanced). |
| max_concurrent_requests | Integer | Maximum number of concurrent API requests. Default: 3 (advanced). |
| top_p | Float | Nucleus sampling parameter. Default: 1 (advanced). |
| random_seed | Integer | Seed for random number generation. Default: 1 (advanced). |
| safe_mode | Boolean | Enables safe mode for content generation (advanced). |
Outputs
| Name | Type | Description |
|---|---|---|
| model | LanguageModel | An instance of ChatMistralAI configured with the specified parameters. |
Novita AI
This component generates text using Novita AI's language models.
For more information, see Novita AI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| api_key | SecretString | Your Novita AI API Key. |
| model | String | The id of the Novita AI model to use. |
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
| top_p | Float | Controls the nucleus sampling. Range: [0.0, 1.0]. Default: 1.0. |
| frequency_penalty | Float | Controls the frequency penalty. Range: [0.0, 2.0]. Default: 0.0. |
| presence_penalty | Float | Controls the presence penalty. Range: [0.0, 2.0]. Default: 0.0. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of Novita AI model configured with the specified parameters. |
NVIDIA
This component generates text using NVIDIA LLMs.
For more information, see NVIDIA AI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens (advanced). |
| model_name | String | The name of the NVIDIA model to use. Default: mistralai/mixtral-8x7b-instruct-v0.1. |
| base_url | String | The base URL of the NVIDIA API. Default: https://integrate.api.nvidia.com/v1. |
| nvidia_api_key | SecretString | The NVIDIA API Key for authentication. |
| temperature | Float | Controls randomness in the output. Default: 0.1. |
| seed | Integer | The seed controls the reproducibility of the job (advanced). Default: 1. |
Outputs
| Name | Type | Description |
|---|---|---|
| model | LanguageModel | An instance of ChatNVIDIA configured with the specified parameters. |
Ollama
This component generates text using Ollama's language models.
For more information, see Ollama documentation.
Inputs
| Name | Display Name | Info |
|---|---|---|
| Base URL | Base URL | Endpoint of the Ollama API. |
| Model Name | Model Name | The model name to use. |
| Temperature | Temperature | Controls the creativity of model responses. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of an Ollama model configured with the specified parameters. |
OpenAI
This component generates text using OpenAI's language models.
For more information, see OpenAI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| api_key | SecretString | Your OpenAI API Key. |
| model | String | The name of the OpenAI model to use. Options include "gpt-3.5-turbo" and "gpt-4". |
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.7. |
| top_p | Float | Controls the nucleus sampling. Range: [0.0, 1.0]. Default: 1.0. |
| frequency_penalty | Float | Controls the frequency penalty. Range: [0.0, 2.0]. Default: 0.0. |
| presence_penalty | Float | Controls the presence penalty. Range: [0.0, 2.0]. Default: 0.0. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of OpenAI model configured with the specified parameters. |
OpenRouter
This component generates text using OpenRouter's unified API for multiple AI models from different providers.
For more information, see OpenRouter documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| api_key | SecretString | Your OpenRouter API key for authentication. |
| site_url | String | Your site URL for OpenRouter rankings (advanced). |
| app_name | String | Your app name for OpenRouter rankings (advanced). |
| provider | String | The AI model provider to use. |
| model_name | String | The specific model to use for chat completion. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 2.0]. Default: 0.7. |
| max_tokens | Integer | The maximum number of tokens to generate (advanced). |
输��出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatOpenAI实例。 |
Perplexity
This component generates text using Perplexity's language models.
For more information, see Perplexity documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| model_name | String | The name of the Perplexity model to use. Options include various Llama 3.1 models. |
| max_output_tokens | Integer | The maximum number of tokens to generate. |
| api_key | SecretString | The Perplexity API Key for authentication. |
| temperature | Float | Controls randomness in the output. Default: 0.75. |
| top_p | Float | The maximum cumulative probability of tokens to consider when sampling (advanced). |
| n | Integer | Number of chat completions to generate for each prompt (advanced). |
| top_k | Integer | Number of top tokens to consider for top-k sampling. Must be positive (advanced). |
Outputs
| Name | Type | Description |
|---|---|---|
| model | LanguageModel | An instance of ChatPerplexity configured with the specified parameters. |
Qianfan
This component generates text using Qianfan's language models.
For more information, see Qianfan documentation.
SambaNova
This component generates text using SambaNova LLMs.
For more information, see Sambanova Cloud documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| sambanova_url | String | Base URL path for API requests. Default: https://api.sambanova.ai/v1/chat/completions. |
| sambanova_api_key | SecretString | Your SambaNova API Key. |
| model_name | String | The name of the Sambanova model to use. Options include various Llama models. |
| max_tokens | Integer | The maximum number of tokens to generate. Set to 0 for unlimited tokens. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 1.0]. Default: 0.07. |
输出参�数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | LanguageModel | An instance of SambaNova model configured with the specified parameters. |
VertexAI
This component generates text using Vertex AI LLMs.
For more information, see Google Vertex AI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| credentials | File | JSON credentials file. Leave empty to fallback to environment variables. File type: JSON. |
| model_name | String | The name of the Vertex AI model to use. Default: "gemini-1.5-pro". |
| project | String | The project ID (advanced). |
| location | String | The location for the Vertex AI API. Default: "us-central1" (advanced). |
| max_output_tokens | Integer | The maximum number of tokens to generate (advanced). |
| max_retries | Integer | Maximum number of retries for API calls. Default: 1 (advanced). |
| temperature | Float | Controls randomness in the output. Default: 0.0. |
| top_k | Integer | The number of highest probability vocabulary tokens to keep for top-k-filtering (advanced). |
| top_p | Float | The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling. Default: 0.95 (advanced). |
| verbose | Boolean | Whether to print verbose output. Default: False (advanced). |
Outputs
| Name | Type | Description |
|---|---|---|
| model | LanguageModel | An instance of ChatVertexAI configured with the specified parameters. |
xAI
This component generates text using xAI models like Grok.
For more information, see the xAI documentation.
Inputs
| Name | Type | Description |
|---|---|---|
| max_tokens | Integer | Maximum number of tokens to generate. Set to 0 for unlimited. Range: 0-128000. |
| model_kwargs | Dictionary | Additional keyword arguments for the model. |
| json_mode | Boolean | If True, outputs JSON regardless of passing a schema. |
| model_name | String | The xAI model to use. Default: grok-2-latest. |
| base_url | String | Base URL for API requests. Default: https://api.x.ai/v1. |
| api_key | SecretString | Your xAI API key for authentication. |
| temperature | Float | Controls randomness in the output. Range: [0.0, 2.0]. Default: 0.1. |
| seed | Integer | Controls reproducibility of the job. |
输出参数
| 名称 | 类型 | 说明 |
|---|---|---|
| model | 语言模型 | 使用指定参数配置的ChatOpenAI实例。 |