处理组件在流程中处理和转换数据。
在这个流程中,拆分文本处理组件将传入的数据拆分成块,以嵌入到向量存储组件中。
该组件提供对块大小、重叠度和分隔符的控制,这些参数会影响向量存储检索结果的上下文和粒度。
Combine text
This component concatenates two text sources into a single text chunk using a specified delimiter.
| Name | Display Name | Info |
|---|
| first_text | First Text | The first text input to concatenate. |
| second_text | Second Text | The second text input to concatenate. |
| delimiter | Delimiter | A string used to separate the two text inputs. Defaults to a space. |
| Name | Display Name | Info |
|---|
| message | Message | A Message object containing the combined text. |
This component combines multiple data sources into a single unified Data object.
The component iterates through the input list of data objects, merging them into a single data object. If the input list is empty, it returns an empty data object. If there's only one input data object, it returns that object unchanged. The merging process uses the addition operator to combine data objects.
| Name | Display Name | Info |
|---|
| data | Data | A list of data objects to be merged. |
| Name | Display Name | Info |
|---|
| merged_data | Merged Data | A single Data object containing the combined information from all input data objects. |
This component performs the following operations on Pandas DataFrame:
| Operation | Description | Required Inputs |
|---|
| Add Column | Adds a new column with a constant value | new_column_name, new_column_value |
| Drop Column | Removes a specified column | column_name |
| Filter | Filters rows based on column value | column_name, filter_value |
| Head | Returns first n rows | num_rows |
| Rename Column | Renames an existing column | column_name, new_column_name |
| Replace Value | Replaces values in a column | column_name, replace_value, replacement_value |
| Select Columns | Selects specific columns | columns_to_select |
| Sort | Sorts DataFrame by column | column_name, ascending |
| Tail | Returns last n rows | num_rows |
| Name | Display Name | Info |
|---|
| df | DataFrame | The input DataFrame to operate on. |
| operation | Operation | Select the DataFrame operation to perform. Options: Add Column, Drop Column, Filter, Head, Rename Column, Replace Value, Select Columns, Sort, Tail |
| column_name | Column Name | The column name to use for the operation. |
| filter_value | Filter Value | The value to filter rows by. |
| ascending | Sort Ascending | Whether to sort in ascending order. |
| new_column_name | New Column Name | The new column name when renaming or adding a column. |
| new_column_value | New Column Value | The value to populate the new column with. |
| columns_to_select | Columns to Select | List of column names to select. |
| num_rows | Number of Rows | Number of rows to return (for head/tail). Default: 5 |
| replace_value | Value to Replace | The value to replace in the column. |
| replacement_value | Replacement Value | The value to replace with. |
| Name | Display Name | Info |
|---|
| output | DataFrame | The resulting DataFrame after the operation. |
This component filters a Data object based on a list of keys.
| Name | Display Name | Info |
|---|
| data | Data | Data object to filter. |
| filter_criteria | Filter Criteria | List of keys to filter by. |
| Name | Display Name | Info |
|---|
| filtered_data | Filtered Data | A new Data object containing only the key-value pairs that match the filter criteria. |
The Filter values component filters a list of data items based on a specified key, filter value, and comparison operator.
| Name | Display Name | Info |
|---|
| input_data | Input data | The list of data items to filter. |
| filter_key | Filter Key | The key to filter on, for example, 'route'. |
| filter_value | Filter Value | The value to filter by, for example, 'CMIP'. |
| operator | Comparison Operator | The operator to apply for comparing the values. |
| Name | Display Name | Info |
|---|
| filtered_data | Filtered data | The resulting list of filtered data items. |
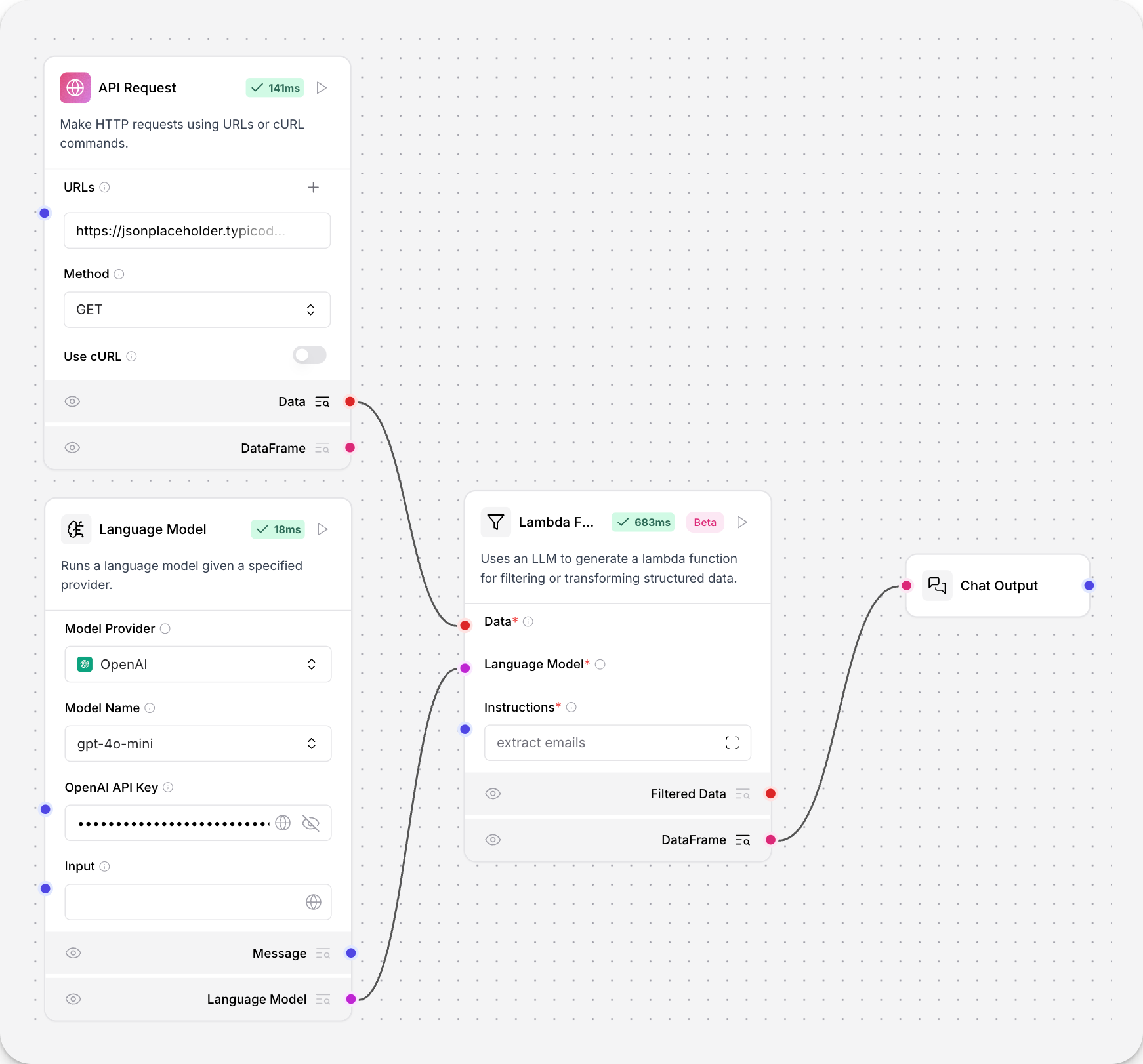
This component uses an LLM to generate a Lambda function for filtering or transforming structured data.
To use the Lambda filter component, you must connect it to a Language Model component, which the component uses to generate a function based on the natural language instructions in the Instructions field.
This example gets JSON data from the https://jsonplaceholder.typicode.com/users API endpoint.
The Instructions field in the Lambda filter component specifies the task extract emails.
The connected LLM creates a filter based on the instructions, and successfully extracts a list of email addresses from the JSON data.
| Name | Display Name | Info |
|---|
| data | Data | The structured data to filter or transform using a Lambda function. |
| llm | Language Model | The connection port for a Model component. |
| filter_instruction | Instructions | Natural language instructions for how to filter or transform the data using a Lambda function, such as Filter the data to only include items where the 'status' is 'active'. |
| sample_size | Sample Size | For large datasets, the number of characters to sample from the dataset head and tail. |
| max_size | Max Size | The number of characters for the data to be considered "large", which triggers sampling by the sample_size value. |
| Name | Display Name | Info |
|---|
| filtered_data | Filtered Data | The filtered or transformed Data object. |
| dataframe | DataFrame | The filtered data as a DataFrame. |
This component routes requests to the most appropriate LLM based on OpenRouter model specifications.
| Name | Display Name | Info |
|---|
| models | Language Models | List of LLMs to route between |
| input_value | Input | The input message to be routed |
| judge_llm | Judge LLM | LLM that will evaluate and select the most appropriate model |
| optimization | Optimization | Optimization preference (quality/speed/cost/balanced) |
| Name | Display Name | Info |
|---|
| output | Output | The response from the selected model |
| selected_model | Selected Model | Name of the chosen model |
This component converts Message objects to Data objects.
| Name | Display Name | Info |
|---|
| message | Message | The Message object to convert to a Data object. |
| Name | Display Name | Info |
|---|
| data | Data | The converted Data object. |
This component formats DataFrame or Data objects into text using templates, with an option to convert inputs directly to strings using stringify.
To use this component, create variables for values in the template the same way you would in a Prompt component. For DataFrames, use column names, for example Name: {Name}. For Data objects, use {text}.
| Name | Display Name | Info |
|---|
| stringify | Stringify | Enable to convert input to a string instead of using a template. |
| template | Template | Template for formatting using variables in curly brackets. For DataFrames, use column names (e.g. Name: {Name}). For Data objects, use {text}. |
| input_data | Data or DataFrame | The input to parse - accepts either a DataFrame or Data object. |
| sep | Separator | String used to separate rows/items. Default: newline. |
| clean_data | Clean Data | When stringify is enabled, cleans data by removing empty rows and lines. |
| Name | Display Name | Info |
|---|
| parsed_text | Parsed Text | The resulting formatted text as a Message object. |
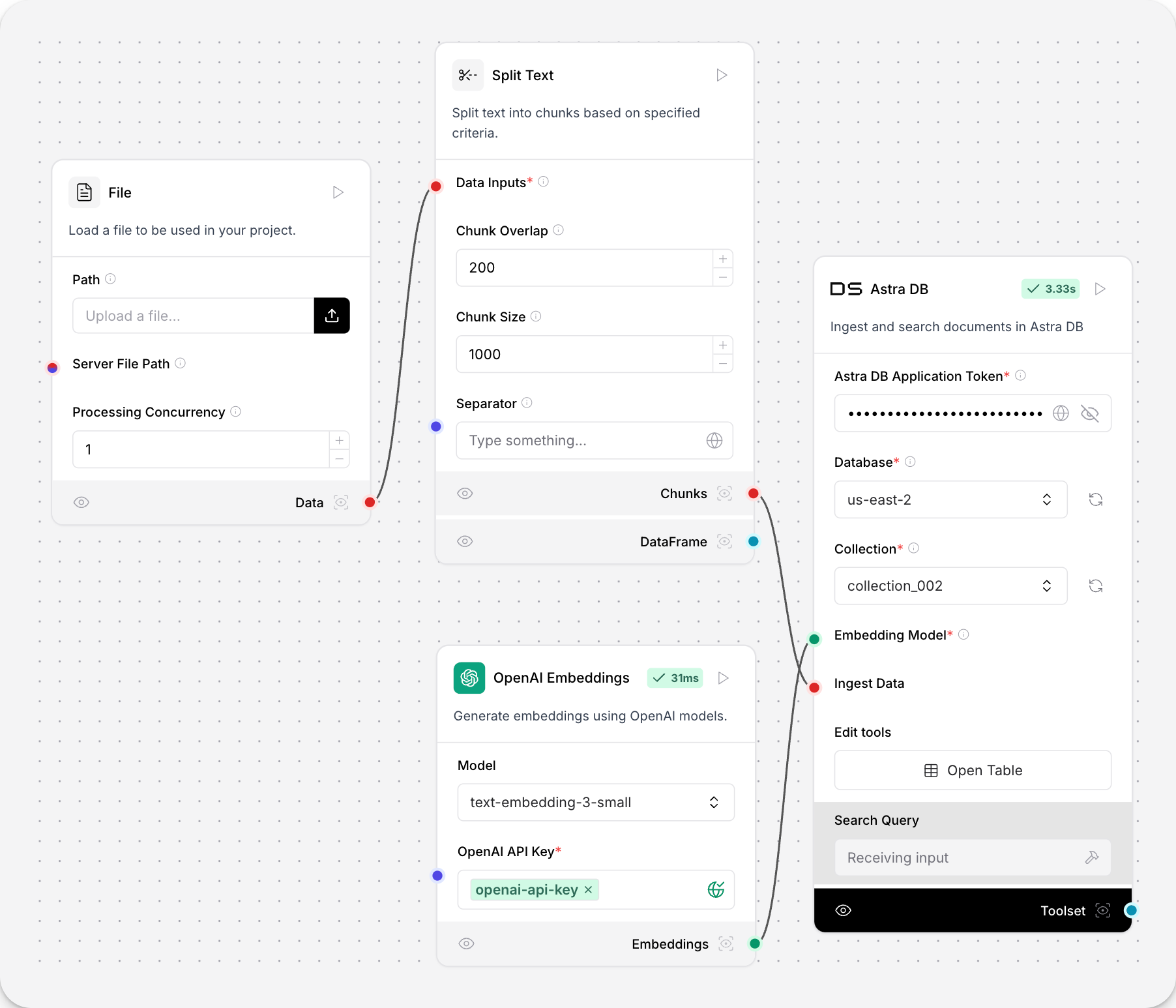
Split text
This component splits text into chunks based on specified criteria.
| Name | Display Name | Info |
|---|
| data_inputs | Input Documents | The data to split.The component accepts Data or DataFrame objects. |
| chunk_overlap | Chunk Overlap | The number of characters to overlap between chunks. Default: 200. |
| chunk_size | Chunk Size | The maximum number of characters in each chunk. Default: 1000. |
| separator | Separator | The character to split on. Default: newline. |
| text_key | Text Key | The key to use for the text column (advanced). Default: text. |
| Name | Display Name | Info |
|---|
| chunks | Chunks | List of split text chunks as Data objects. |
| dataframe | DataFrame | List of split text chunks as DataFrame objects. |
This component dynamically updates or appends data with specified fields.
| Name | Display Name | Info |
|---|
| old_data | Data | The records to update |
| number_of_fields | Number of Fields | Number of fields to add (max 15) |
| text_key | Text Key | Key for text content |
| text_key_validator | Text Key Validator | Validates text key presence |
| Name | Display Name | Info |
|---|
| data | Data | Updated Data objects. |